@George, have there been any major changes in the repeat component in SC since Wappler ver. 2? It feels like the multi-insert has become slower.
Question to the community. Has anyone worked with large data arrays (insert/update)? A large array is more than 500 thousand records. How do you insert records into the database?
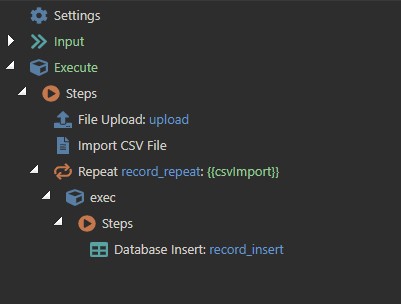
I measured the insert speed using a pre-prepared csv file with 12,364 records. The server action is extremely simple:
Total:
12,000 records are inserted into the database for 6 minutes. It turns out that it will take 5 hours to insert 600 thousand records. It’s incredibly long.
How to work in a Wappler with a large amount of data without using custom solutions?
If it is a one-off seeding, I do it outside of Wappler.
If it needs to be a web page upload, then I break it into smaller chunks and/or hand it off to a queue (custom module) so the user is not left waiting. At the end of the job, I notify the user.
I’m not sure if you would consider it a custom solution, but perhaps you could use LOAD DATA INFILE which is a very fast method of importing CSV files, if it’s suitable.
I was finding importing 10-20k records very slow and had to fiddle with PHP setting to prevent time-outs etc. I switched to LOAD DATA INFILE and thought it hadn’t worked - the timer I had included in the SA file returned zero seconds. In fact the import had worked, but the process took less than a second. It’s possible to import 10s or even 100s of thousands of records per second with this method.
I created a custom PHP file to do this and called it within a SA as an API. However, this was quite a while ago, before custom queries were available in Wappler. When custom queries appeared, I thought I would replace my PHP file. This worked, but I had to modify a Wappler file, with @patrick’s help, but only using some ‘incorrect’ syntax. I’m not quite sure what the issue was, but in any case, I decided to stick with my original solution. It might be that it would work now, simply using a custom query. There have been quite a few changes in the relevant Wappler file since I raised the issue here.
Using LOAD DATA INFILE would be the fastest way to import bulk data from an csv. Doing an insert for each data record will be very slow when importing such a large dataset, it is already faster to do a bulk insert using INSERT INTO, but that also would not be able to do 50k records at once.
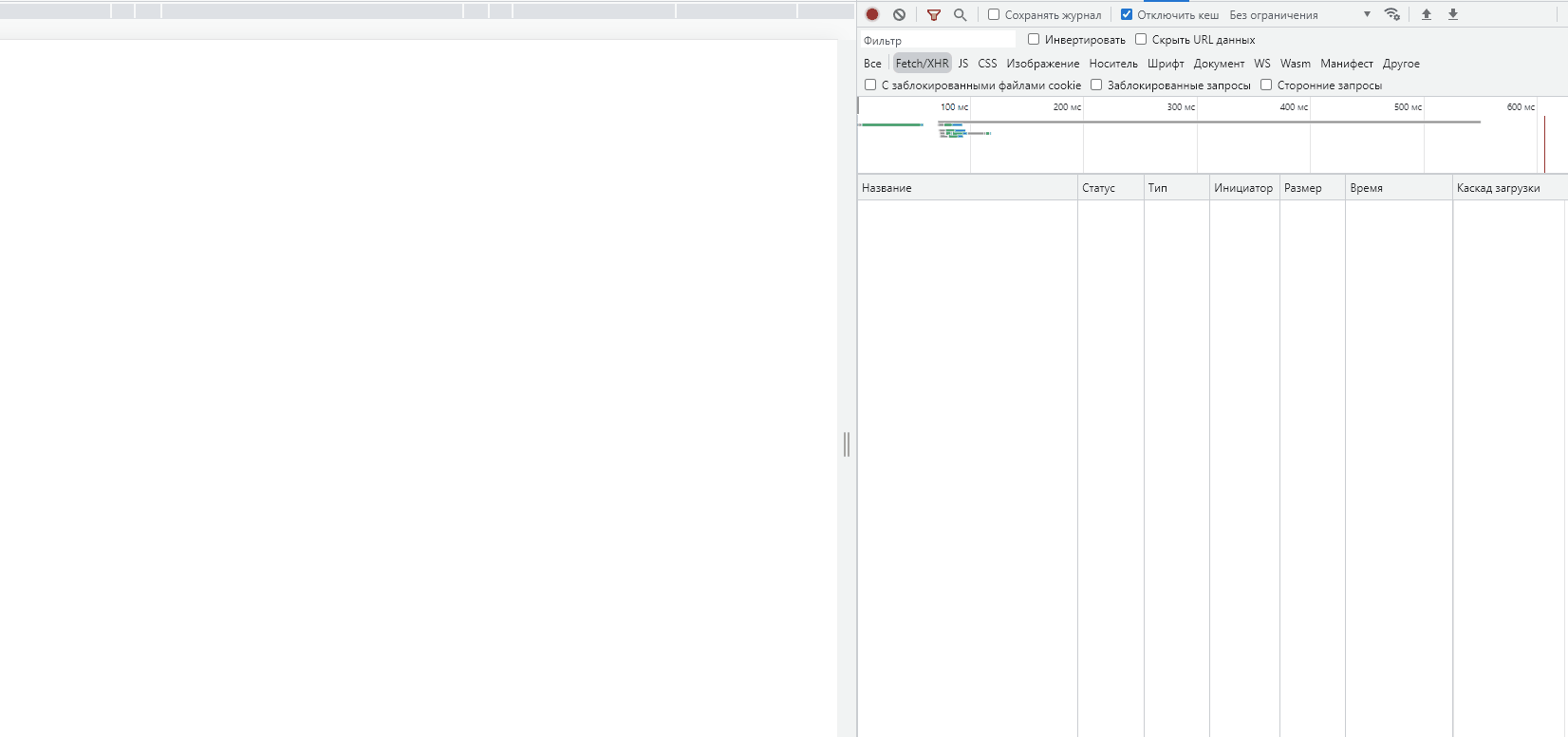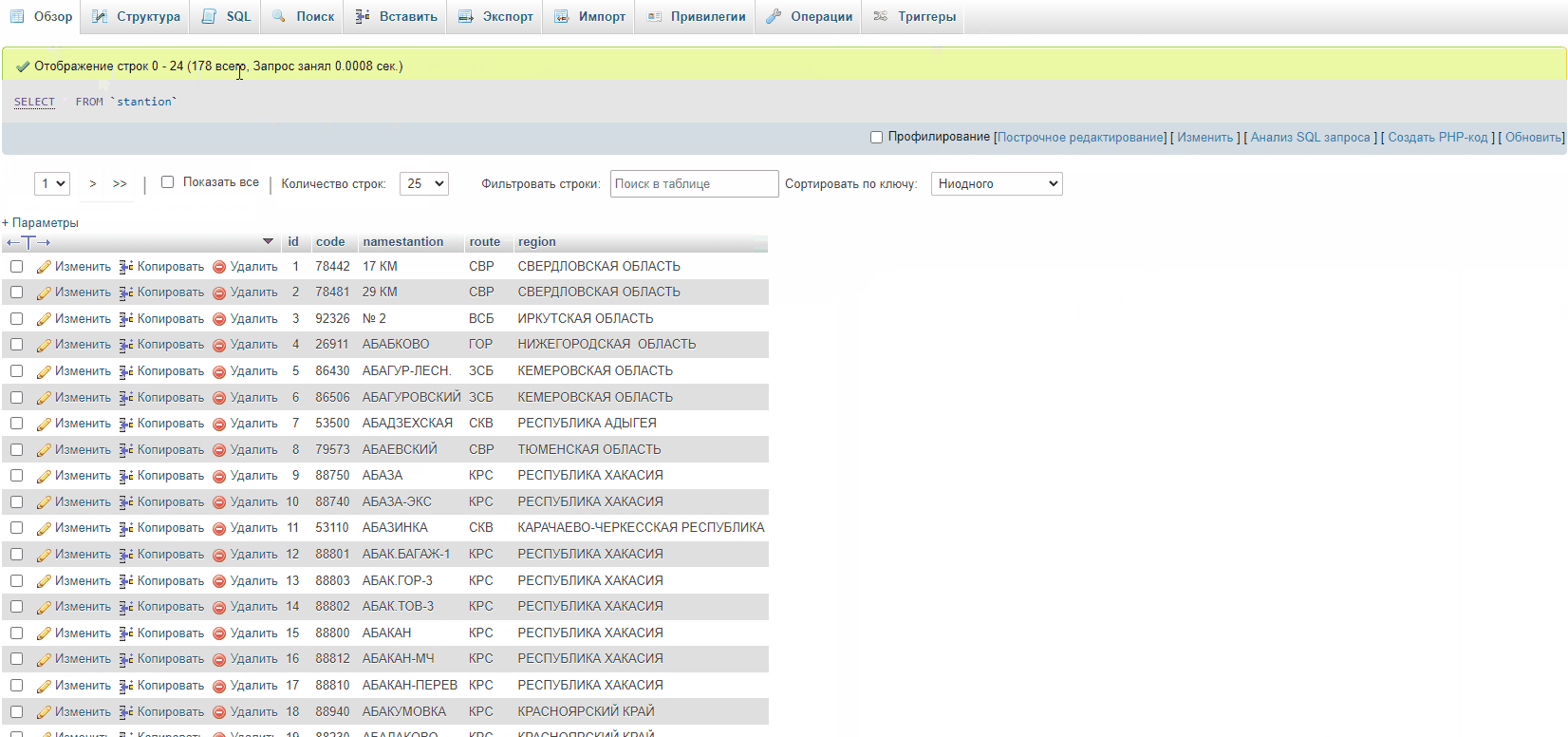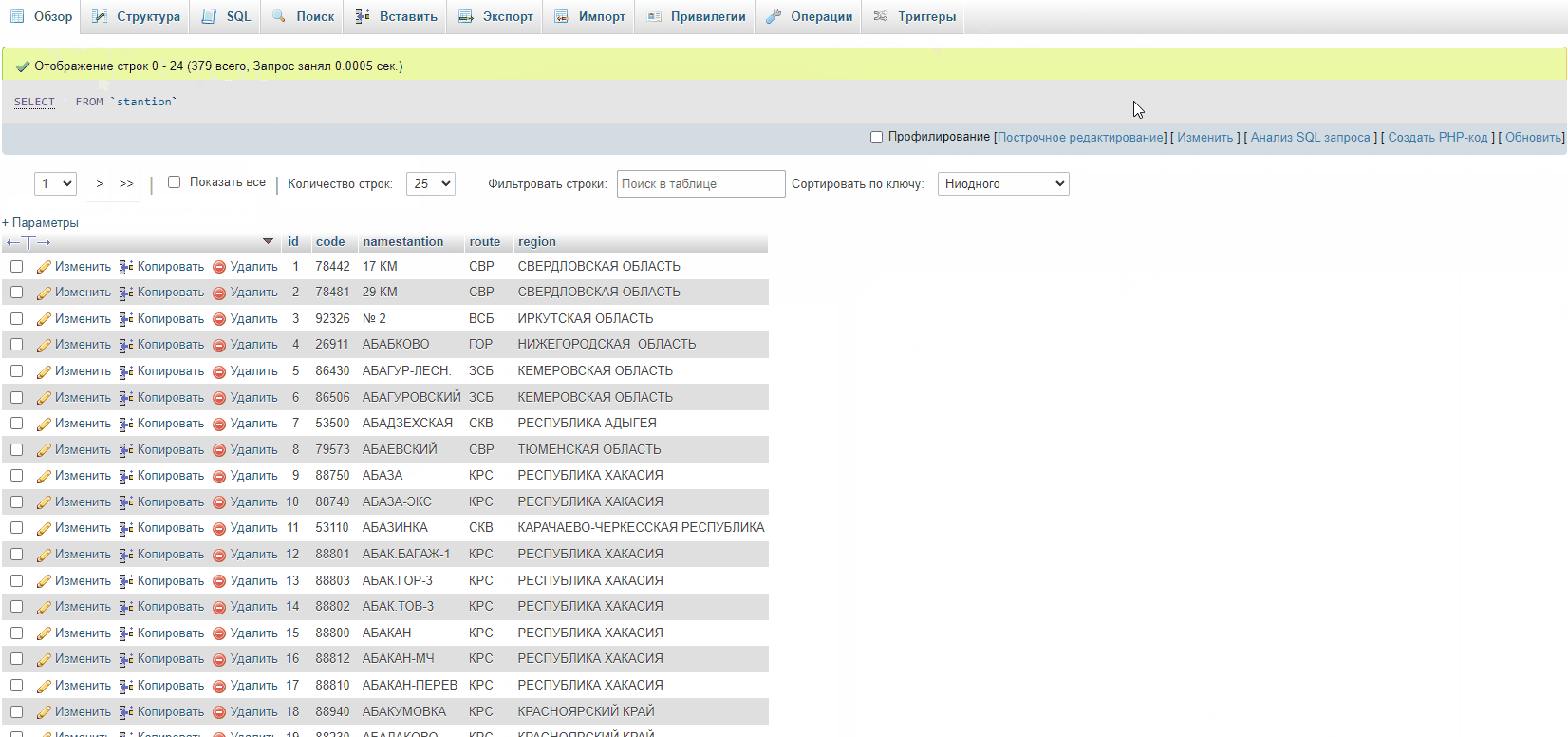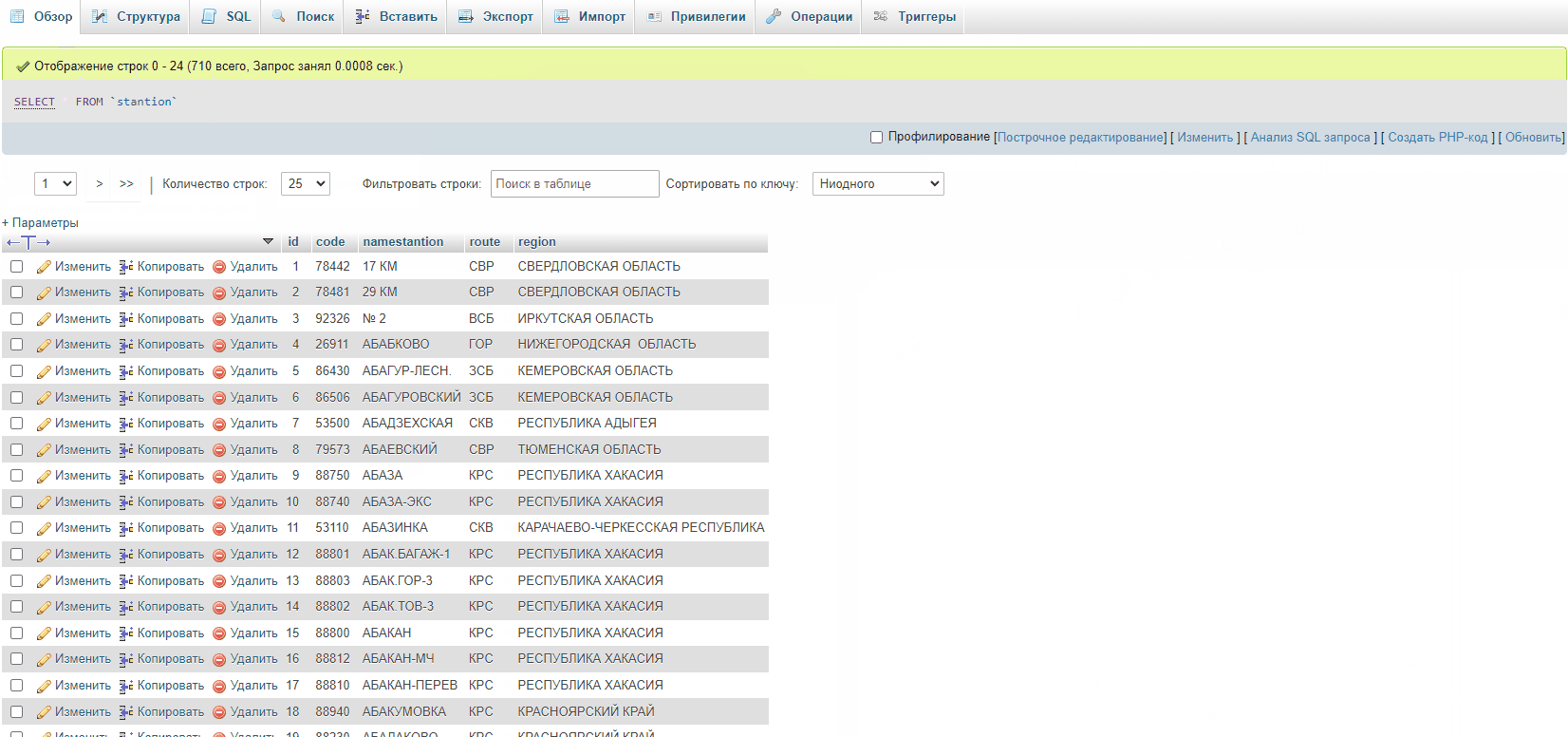
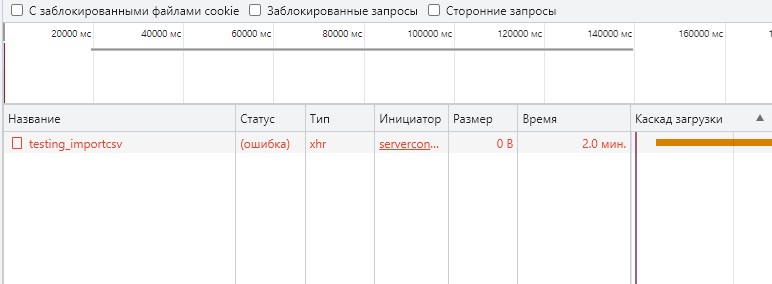
@TomD and @patrick thank you for a great solution. In the case of csv import, the method works perfectly! I inserted all 12364 records into the database in 690 milliseconds (and this is taking into account the upload of the file itself to the server). Thus, 600 thousand records will be inserted into the database in less than a minute. This is a really great, high-performance solution.
But I would like to move away from this particular case and consider the general case. What if we import data not from a csv file, but from a third-party API in json format? Is there a possibility, as in the example with csv, of high-performance insertion of json records that came from an external API?
These kind of imports are very database specific. To import third-party API in JSON format it depends on how the data is structured. If it is an array with objects you could probably use our csv export first and then insert the csv in the database.
Сергей, you can drag and drop the screenshots directly here in the forum so they are displayed directly, better than just links to some google drive folders.
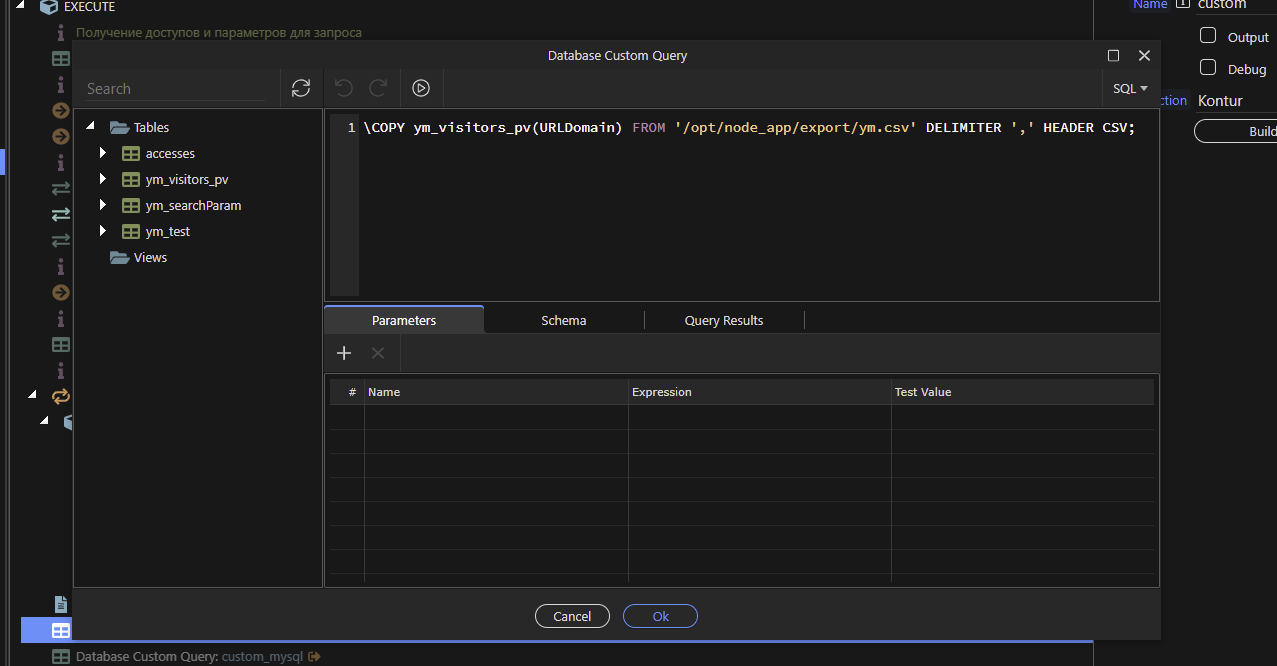
The first error is that your database user doesn’t have enough permissions to do the COPY action. The second is that the path is incorrect, on a linux system you need to use / instead of \. Also I don’t know if postgres requires a full path or that it works fine with relative paths.
When using COPY instead of \COPY, a security error will occur not because the user lacks real rights, but because the file is on another server. The database server and the web application server are two physically different servers. In this case, it is necessary to specify postgresql that the file needs to be searched on the client side, which is the web application server.
Exactly the same situation occurs in mysql with LOAD DATA INFILE. If you use the command in this form, the same security error occurs, since there is no file on the database server. In order for mysql to correctly use the file from the web application server, it is enough to add LOCAL to the command to get LOAD DATA LOCAL INFILE. However, unlike \COPY in postgresql, LOAD DATA LOCAL INFILE works fine and no errors occur.
Didn’t know that the \COPY was for the client side, does it also depend on the client driver to support this? I don’t have very much experience with PostgreSQL.
You could create your own server action for the bulk import, here an sample on how to do it with nodejs:
var fs = require('fs')
var { Pool } = require('pg')
var copyFrom = require('pg-copy-streams').from
var pool = new Pool()
pool.connect(function (err, client, done) {
var stream = client.query(copyFrom('COPY my_table FROM STDIN'))
var fileStream = fs.createReadStream('some_file.tsv')
fileStream.on('error', done)
stream.on('error', done)
stream.on('finish', done)
fileStream.pipe(stream)
})


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}