Can anyone guess when we denied LLM scraper bots access to one of our Projects...
![]()
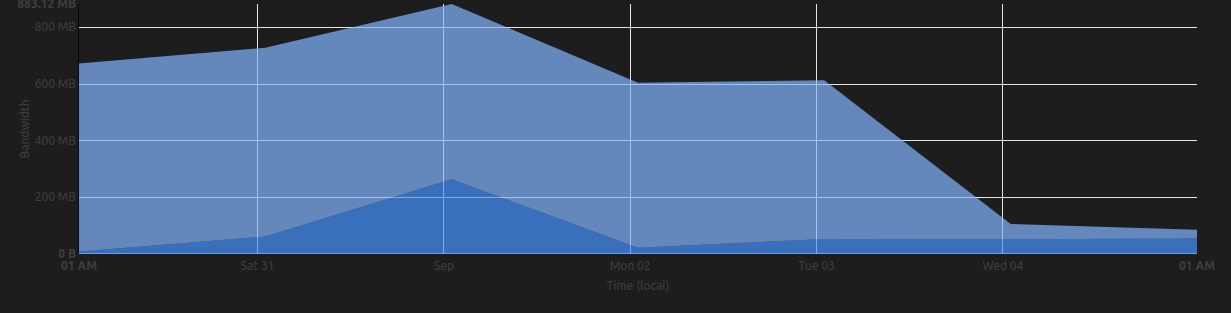
For context purposes. All media is hosted on S3, most assets are CDN based. It seems these bots hit your sitemap initially (and man they don't stop, they stick around and repeat and repeat their scraping). This Project being a directory has thousands of entries. Essentially most of the bandwidth consumed by these bots is text based. That is one is a hell of a lot of text (the page layouts themselves don't weigh a lot at all)... These bots are a modern day pest and out of control...
I've just had a similar issue with bots which targeted an events calendar and were relentless. We had to block them just to bring the server load back to normal levels.
This was similar the load went up dramatically (first we saw a significant increase in database activity) as well as the bandwidth which was a real sign of something happening as despite a very healthy User base we have never hit these levels even on the busiest days. Just very happy we no longer have to pay for bandwidth like we used to do. In the 'old' days we had an incredibly popular gaming website which cost us thousands of Pounds a month to host just because of bandwidth usage. Happy to say these days with unlimited bandwidth this is not an issue. Still we don't want this activity and in no way have we agreed to it, essentially it is intellectual property theft... These LLM companies really need reigning in.
How did you deny the bots?
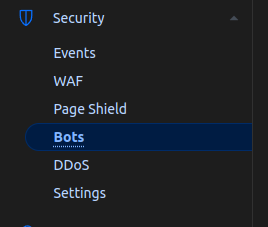
We did this using a new Cloudflare feature:
Previously we had tried using robots.txt to do this but the bots simply ignore any directives specified within it (they are a law un-to-themselves). Recently Cloudflare announced the above, enabling this had an immediate and dramatic effect, as seen in the above graph.
This setting can be found within (available in the Free Tier also):
Does that block search engine crawlers?
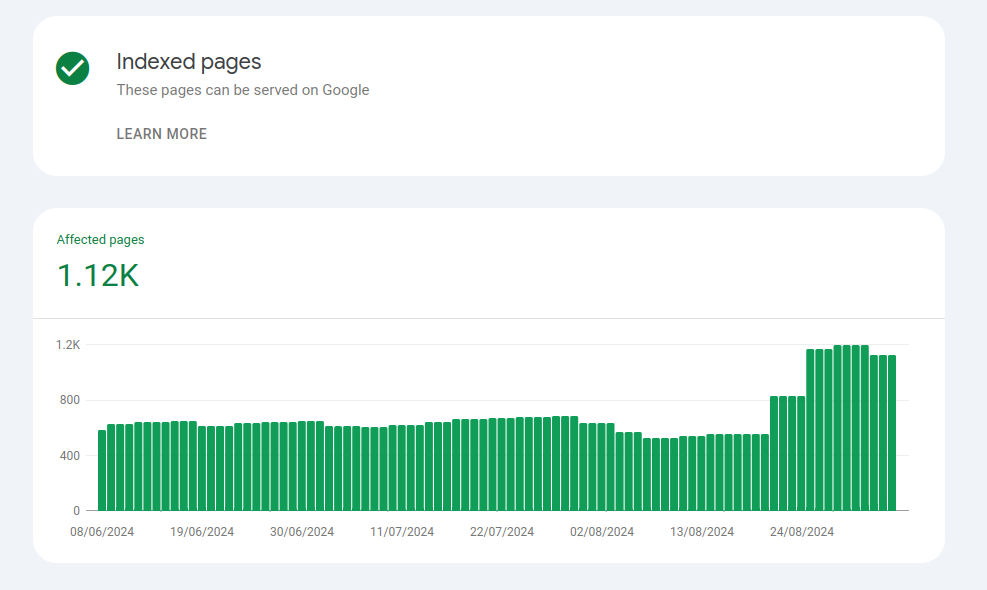
No not at all. Site is indexed correctly with no loss in indexed/served pages.
Damn I sound like a Cloudflare pimp... They have an enhancement for that too (accessible on the Free Tier). Which works incredibly well. We see new pages indexed in around four to six hours, blog entries even faster, sometimes within an hour or two (site built entirely in Wappler).
I use this in robots.txt
User-agent: CCBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Google-Other
Disallow: /
User-agent: Google-Other-image
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: Omgili
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: facebookexternalhit
Disallow: /
User-agent: Diffbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: ImagesiftBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Timpibot
Disallow: /
User-agent: Webzio-Extended
Disallow: /
User-agent: YouBot
Disallow: /
User-agent: img2dataset
Disallow: /
User-agent: scrapy
Disallow: /
User-agent: PetalBot
Disallow: /
User-agent: FriendlyCrawler
Disallow: /
User-agent:Ai2Bot
Disallow: /
User-agent:Ai2Bot-Dolma
Disallow: /
User-agent:ValenPublicWebCrawler
Disallow: /
An update nightmare every time a new bot appears/disappears ![]()
Nobody said life as a webdev was easy ![]()
![]()
![]()
![]()
![]()