This question is specifically regarding Unicode Normalization / Account Takeover on registration forms.
Does Wappler automatically handle ensuring canonical encoding is used across all the text and that no invalid characters are present? or is this something that needs to be manually configured?
The validator should not accept double registration with Unicode signs.
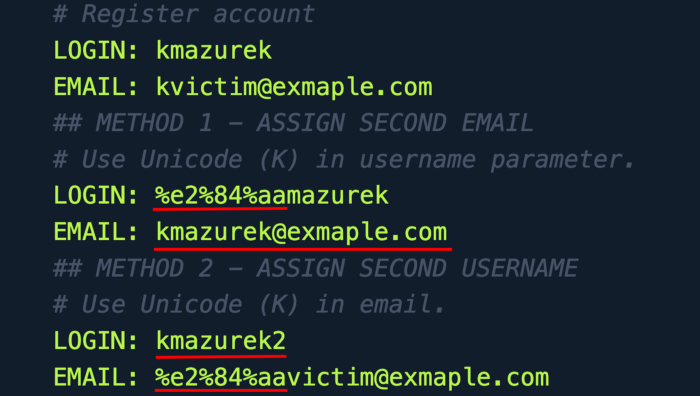
Register account with Unicode letter. As an example:
U+0212A normalizes to K and can be sent URL encoded as %e2%84%aa.
List item An attacker could use this to hijack an existing account by creating the same one with Unicode characters and assigning different sign-in components (email/username/phone number etc.)
List item Records in the database of the old account could be overwritten, which could allow logging in using the new password.
Not sure if it will be an issue, the email indeed looks the same but in javascript when you compare the 2 strings it returns false, so it detects the difference. With databases results can differ depending on the collation used, binary compare would detect the difference.
btw. the U+0212A is the Kelvin sign, it looks like a K but isn’t the same character.
Thanks everyone for the replies on this. I shall do a PoC on my register forms and try to break them with the goal of registering two users with competing information. I will report back!
name1 is Amélie and name2 is Amélie and as you said if you compare them they are different.
You wouldn’t want to allow those two usernames to be saved in the database as someone with malicious intent could abuse the similarity of the usernames.
So for that you would want to use the normalize() function before comparing the post data with the data in the database to disallow additional registrations.
And as @obsidianux the different layers can affect how a password reset is treated for instance.
In summary, adding normalization is a good practice to avoid bad actors abusing similar usernames(visually speaking), but adding normalization adds some complexity to the security of the different layers (browser, server and database) that need to be in sync as how they treat unicode.
The normalize is indeed a good practice, but it is only for normalizing characters that can be represented as a decomposed form, like with umlaut characters.
In the example from the topic the normalize would not work, since it is not the same character represented in a different way. In his example it was a completely different character that visually looks the same as the other character.