For those of you deploying Wappler apps to Caprover, just sharing here a tiny script I made in the last hour, that may or may not be useful to you. By the way, if you’re a beginner, perhaps you’re better using Wappler’s native Docker integration.
This is useful if you use Git and have a separate Wappler Target just for Caprover. You develop while on Development target, and then you have a Caprover Target (here called “Production”) where you configure the production database credentials, debug mode off (as for production), etc…
First-usage instructions:
Create a Git branch “caprover” (git branch caprover)
Do “caprover deploy” and deploy from “caprover” branch
Remove “caprover” branch (git branch -d caprover)
Follow usage instructions
Usage instructions:
While on Development target, commit ALL changes (sorry, it doesn’t work if you have an uncommited file laying around, it will error saying you have uncommitted changes. I’m sure we could work around that, but it requires further thought to ensure no file is unintentionally deleted)
Run “./deploy.bash” on the Terminal (your computer’s terminal, not inside Wappler’s Docker container) (if an error occurs, chmod +x ./deploy.bash)
The script will ask you to switch to Production (Caprover) target, do so on Wappler
Wappler will copy Production files from inside .wappler folder to the root directory
Press Enter on the terminal to continue the script
The script will create a branch “caprover”, and commit ALL changed files (refer to point 4)
The script will call “caprover deploy --default”, which will deploy to the last selected Caprover (remember the first-time instructions?)
Deployment success
The script will git checkout to the branch you were at, and delete the temporary “caprover” branch used for caprover deploy
The script will ask you to switch to Development target
#!/bin/bash
set -e
branch_name="$(git symbolic-ref HEAD 2>/dev/null)" ||
branch_name="(unnamed branch)"
branch_name=${branch_name##refs/heads/}
if [ "$branch_name" = "caprover" ]
then
echo Current branch is caprover, aborting...
exit 1
fi
trap 'echo Error: Please commit all git changes' ERR
git diff-index --quiet HEAD --
trap - ERR
echo Please switch Wappler target to Production now, and then press enter
read
git checkout -b caprover
git commit -a -m "Caprover"
caprover deploy --default
git checkout $branch_name
git branch -D caprover
echo Please switch Wappler target to Development now
Possible future improvements:
Automatically check which Wappler Target the user is now at
Automatically proceed script once user changes Wappler target
Wishes for the Wappler team:
Ability to programmatically switch between Wappler Targets
Why so complicated? We just keep a master/main branch, and all production related stuff is in environment variables.
Other Globals items can be configured using ENV.
Setting up DB things is a bit tricky, but it all works.
Just push to master to go to production. No need to rely on Wappler target.
I think it was because of a problem connecting to the production database (e.g.: running migrations, viewing data). When you want to connect to the production database from Wappler, how do you do it? It reads database credentials from ENV, but in .env it’s your local database credentials, not remote
We don't use Wappler DB Manager. So for that, I think you should stick to your script.
We use DBeaver or Workbench in our team since it gives better control over the DB. We miss out on migration, but its a trade-off we are happy with.
.env file is something that should not be committed. When running on local, it reads the local .env file for environment variables. When on production, it reads the environment variables you set in Caprover App's AppConfig tab.
Yeah, it's not commited. I'm just saying when using Wappler DB manager, it reads the credentials from .env, which on local computer is the local database. To connect to the production database I'd need to create a new target ("Own Hosting") and specify credentials there - unless you have a suggestion so I can maybe read from "production.env" or something? I vaguely remember you or your brother talking about a "production.env"
Edit: This just made me realize, I've actually commited a Production db.json containing the production credentials
If you want to use DB Manager with production credentials, I don’t know of a way where your credentials dont get exposed in Git.
Maybe @George can suggest something.
Best to set it as an option in Docker type hosting model - so that devlopment & production environment are same.
Although I would prefer to have a better environment variables UI first, since in our projects it plays a critical role as described above.
In most of our deployments, we use captaindefinition file with a captaindockerfile.
I don’t know how to make YML work with CapRover, which is what Wappler generates for current Docker targets.
Caprover has a CLI similar to heroku although much more limited in functionality so I guess you could just start by integrating the CLI.
Also I don't know what your final plans are for deployment methods as you were looking for alternatives for docker engine.
Have you guys thought about devoting some hours a month as contributors to caprover project to improve the set of features. I think right now it's still maintained by one person and it could be the solution for all Wappler deployment needs.
Also you are aquainted with the underlying tech stack: docker, express, typescript
If there is serious consideration to integrating caprover, then I think Caddy server should also be looked at.
I have a target setup where I have removed traefik in favor of a second container using Caddy that is provisioning certificates in real time rather than at build time. Because it is outside of the Wappler container, it is also providing a maintenance page for outages, manual downs, and deploys. For our wild card cert, it uses dns validation and for all others it does http validation after verifying via our app that we want the domain to be allowed.
I’ve never used caprover, but Caddy sure does everything I’ve needed and is very easy to understand.
Just wanted to drop a note I'm no longer using this script (overcomplicated), and ended up making a feature request here:
My current deployment process I haven't shared yet, it involves a custom Dockerfile that automatically patches Wappler files to read database credentials from environment variables, so I just deploy from the master branch
Right now it’s just the JSON files, patching the JS file for Redis I don’t know how to do it the proper way (aside from string substitution). I’m using jq to edit the JSON files
I think I edit both the debug variable config as well as the database credentials JSON
Ok. Yeah, redis conf file is a b*tch.
But you should be able to use SC bindings to read ENV variables for the database as those are actually parsed by SC.
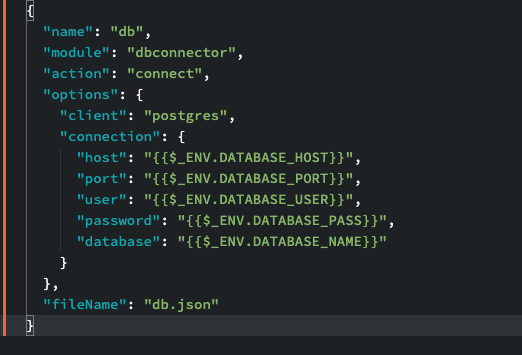
Yes, I replace the credentials with $_ENV and so on. Reason I don’t do it directly at Wappler UI is because it’s the Development target and Wappler sets the credentials of the database automatically and it might override whatever manual changes I do there after an update or settings change
So you use more than one target? I just use Wappler to code and not to deploy, ergo I only have one target. My deployment starts once I push changes from the development target to my remote git repo. So any connection string, key or whatever else is just an SC binding to read ENV variables. I’m not using any target config.
For me at least this is the most natural way of working. I’m not too fond of the targets thingy as it’s a reminiscence of old FTP deployment and doesn’t fit today’s best practices.
I’ve never had any problem with my db connection files being updated or overwritten.
I think it’s a cool project, but it’s rather new and I don’t know if it’s mature enough. In time it could be a nice option indeed, but right now battle tested caprover seems like the better option.
Both projects are maintained by one person so I’m pretty sure both need help that you guys could offer if that solves your future needs regarding deployment. Maybe you can have a chat with both of them to understand their vision for the software and where they would like to go with it.
Coolify however is still lacking some important features that may or may not be added in the future:
Clusters and scaling
CLI
Integrated monitoring
On the other hand it has some features where it beats caprover:
I just use one target (Development), but the credentials are the ones Wappler set by default. My target is a Docker local target. Interesting you never had your DB connection files updated or overwritten. At this point I’m just going to ride along what Wappler sets and patch it on-the-fly. As a reminder, Wappler doesn’t support $_ENV on the Port field (integer only), so if you try to change settings it might crap out
Related to CapRover and Coolify, funnily enough I’ve checked all of them and none fit the bill for me. Dokku is another consideration, only lacking in GUI (paid) and horizontal scaling (although it does have a proof-of-concept somewhere) - vertical scaling (multiple processes in the same server) is still fine. I trust Dokku for large traffic websites after a bit of tuning in the nginx config and ulimit
Handling backups is still something Wappler would probably have to implement
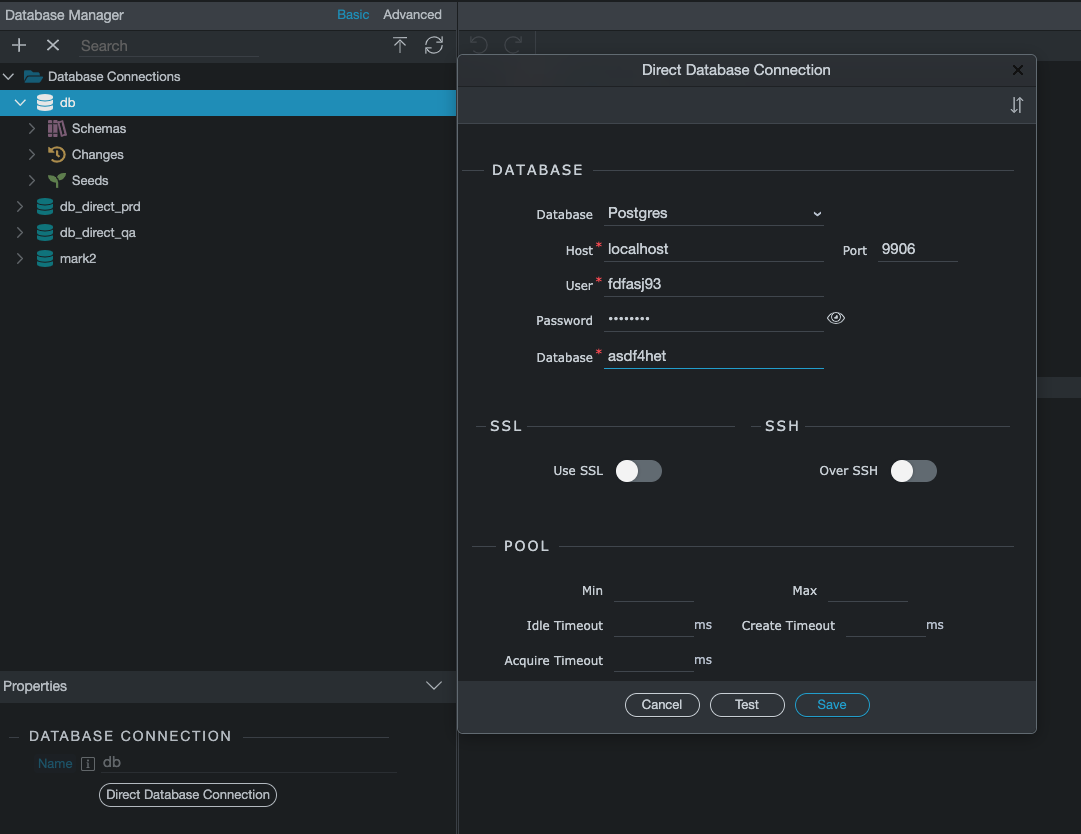
Take into account that Wappler uses two sets of connection strings for any given database. One for Server Connect and another one for the Database Manager. They can be the same, or not.
Server connect
Config files stored in app/modules/connections/
This one can take ENV variables and you can bind the port also. It's also the file that your app relies on.
Database manager
Config files stored in .wappler/targets/your_target/databases. Your app doesn't depend on this one.