I’ve been testing this out for a couple of months or so and it looks like the SEO for what used to be a very well performing site has fallen off a cliff.
The original site was in classic ASP and ran perfectly, the SEO was amazing. We had top rankings on most of the keywords on each page submitted. The complete site was regularly spidered and ranked accordingly.
We ‘upgraded’ the site to run on NodeJS, it still runs perfectly but our SEO is now almost non existent. We’ve lost a lot of traffic as a result.
The main menu at the top of the page and the page footer (hard coded links) are being indexed correctly, however, any page that has dynamically generated links does not get spidered by the search engines. This has to be done manually though the Google Search Console.
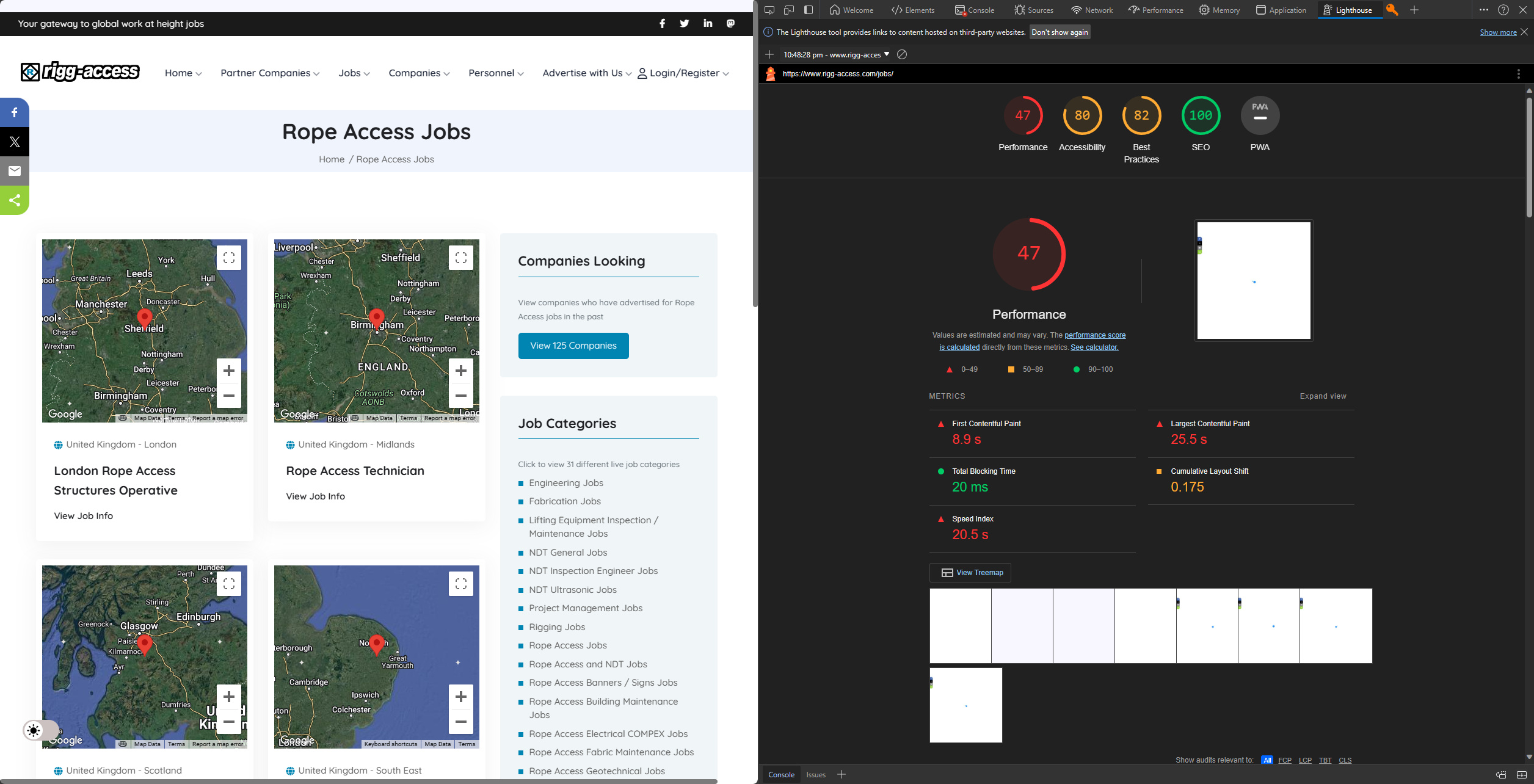
Here is one page that is affected, every single link on this page used to rank well:
The sub menu on the lower right used to perform very well.
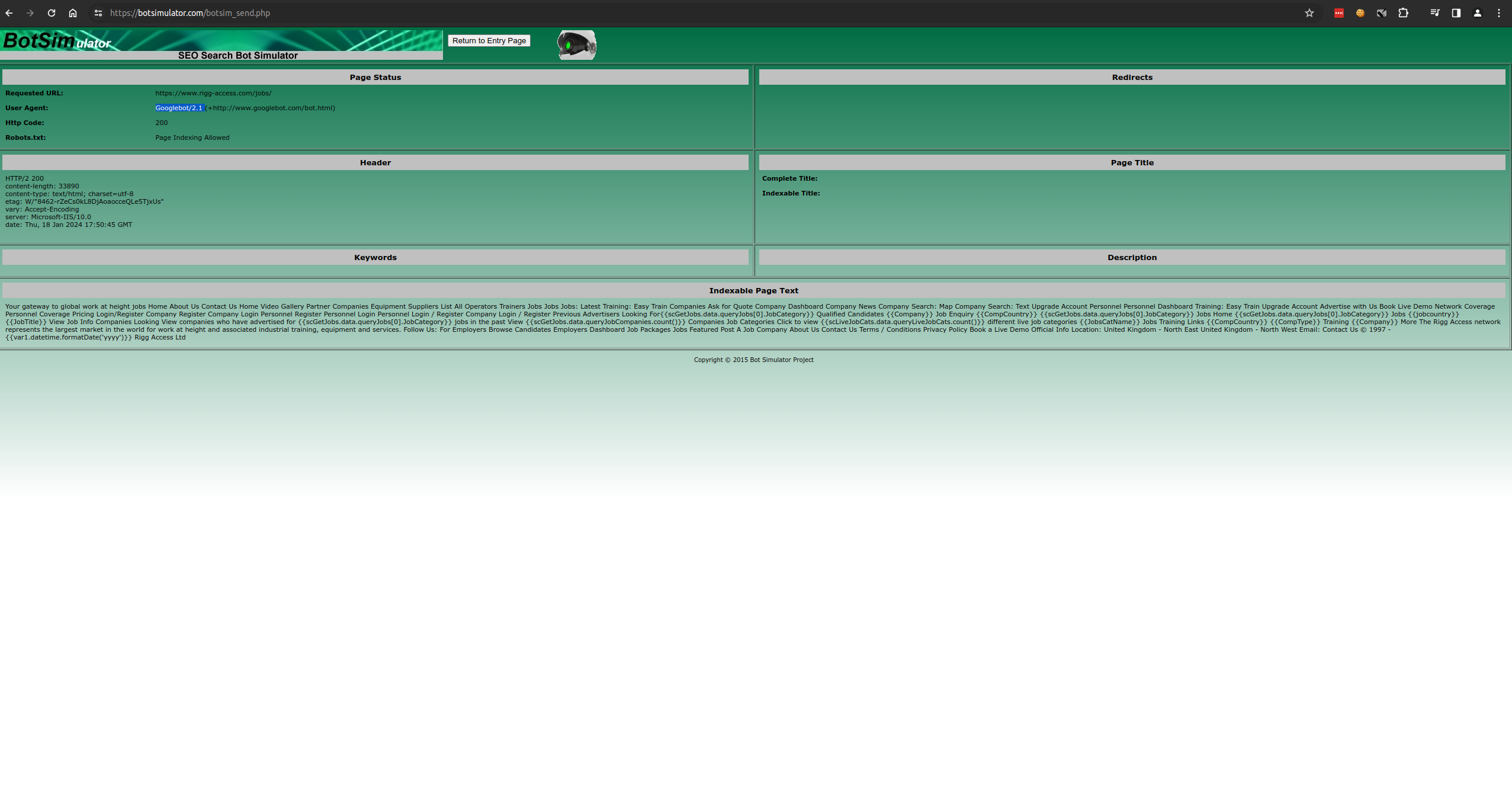
All links on the page above are no longer spidered automatically by Google. To test out, I put the above URL into a random online bot simulator here: https://www.xml-sitemaps.com/se-bot-simulator.html
All the links on the page are not visible to this bot simulator, nor to Google bot.
Has anyone else experienced this? Does anyone have any suggestions on how I can get this page correctly listed without having to manually handball them into Google?
When moving from a very old site to a new one, it is very important to rewrite your old links to new ones. So your old links should redirect to the new ones. Then Google link gradually learn your new links and you won’t loose your good ranking.
If you just switch to complete new links and the older links just stop working, then you will definitely loose SEO ranking so your new links aren’t so trustworthy yet.
Google indexes just fine dynamic links these days, so should be able to follow them and there is no need for extra sitemap xml. The bot simulator you linked, can’t do that so it is giving you wrong results.
Maybe @psweb can churn in with more SEO tips as he is the expert
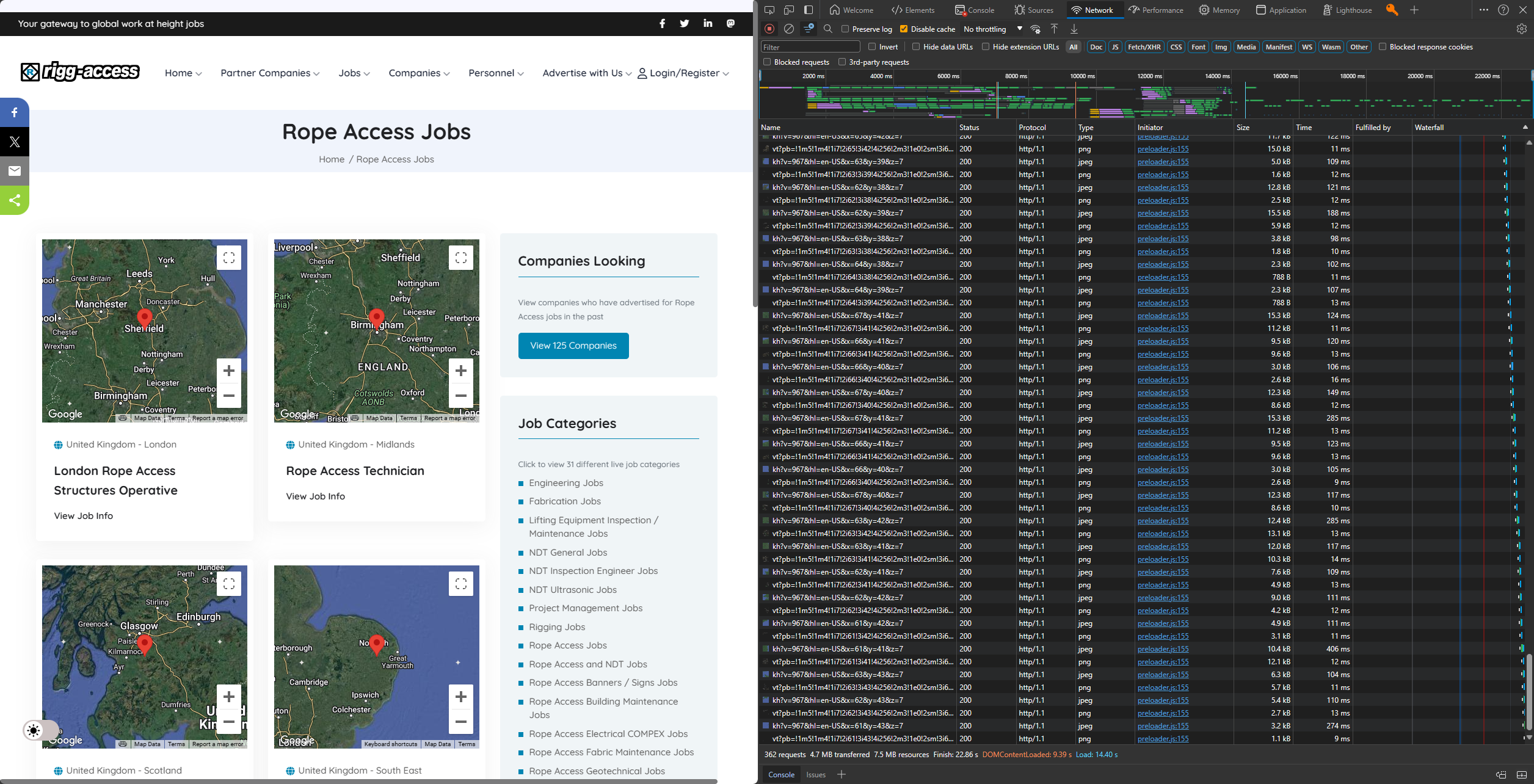
For the Network tab, I did clear the storage, meaning that the Server Worker was void of data.
In this case, it too nearly 10 seconds to load the content into the DOM. One of the reasons is the fact that your host still uses the HTTP/1 protocol. You should see an enormous increase in speed when using the HTTP/2 (even better: HTTP/3) protocol. Talk to your host or go to another host.
Also these “bot simulators” are not to be trusted, none of them. They render nothing like what Google bot sees. The only trusted way to review what the Google bot sees on your page is to use the Google Search Console and the tools available there.
This is the standard Google Bot and not the one used in the Search Console which is the inspection tool bot (they are different), the standard bot does not render dynamic content (aside from server side rendered content). The inspection tool bot does/can render dynamic content (but this is via manual request operation in the console).
This botsimulator thing does not render your page as a google bot. It loads your url by just sending a different user agent - again it’s nothing the google bot sees.
Not sure what could be wrong in your browser, but the data is clearly visible in the source code on both my Windows and Mac computers:
Also i am not sure i understand what do you mean here.
It’s Google themselves explain that their crawler bot renders the js code perfectly fine, and it’s been already many years since this has been happening.
Also Google guys tell you to use the Search Console tools to see how their own bot sees your pages.
There’s no mention of a distinct “indexer bot” separate from the “standard Googlebot”
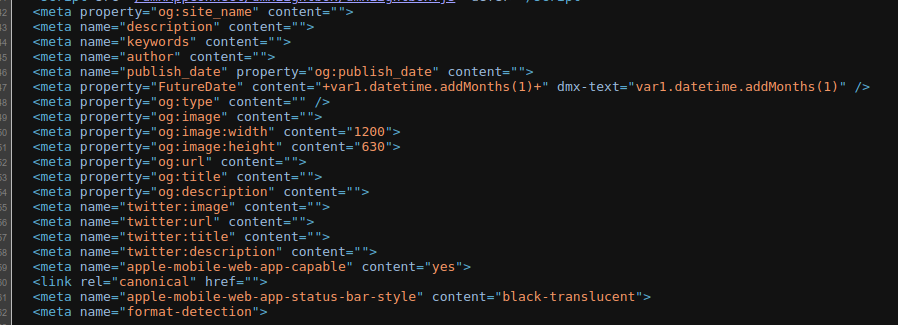
I’m not going to argue but it also does not display the meta tags. Regardless of OS or browser.
Nothing is wrong with my browser it displays every other website correctly. Node, PHP and ASP. All render the meta correctly. So can’t answer for that.
Then why does Google index the site with unrendered JavaScript in many situations? We had this problem ourselves. Results snippets were exposing unrendered content. I’m not making this stuff up it’s just our own experience which I am sharing. After employing an Engineer to review the situation issues were highlighted which we resolved and Google indexes our content correctly.
Example of unrendered snippets in Google results (prior to implementing suggested fixes):
Hi @TMR, my comment maybe is not about why sundely dissapear your SEO rank, but it will help to a proper UX and maybe a better indexing by search crawlers, I hope you don’t mind.
I don’t know if maybe is a client requirement, but the use of Google Maps API to render multiple maps on the frontpage looks like not best way. I suggest that instead on call each map with coordinates, just capture the image url from the same api and store locally in server (asuming that each " Rope Access Jobs is added in a backend"), and replace all that live maps with static image. Only in the details on each one you can maybe use the live map.
With sites that have thousands of dynamically generated pages, business directories, blogs, stores, etc. I believe there is definitely an issue with indexing and rendering. If the pages are static with dynamic content they render a little better but if they are defined (requested) with a specific parameter in the request (and share the same page name) the problem arises…? I don’t know I’m just a dumb developer!
It’s not a Wappler thing, it’s how the front-end js frameworks work in the modern internet.
Google has no issues with JavaScript and rendering it. But it has issues with code errors, not following best practices etc. It’s all explained in the Google SEO documentation.