- When creating the table, have the primary key default to the table name
- When adding a column, if the column is suffixed with _id, default it to an integer
- When adding a column, if the column is suffixed with _date, default to a datetime
- When creating seeds, default the seed name to tablename_date (or add a version number to the project info and use that)
- Automatically add create_by, create_date, update_by, update_date fields (maybe a preference?)
- When creating seeds, provide an option to add the primary key to the seed file (or reset the numbering on the table PK) - creating related files is a pain.
Great suggestions
Great suggestions indeed!
Do you mean to name the primary id field to tablename_id?
2 Likes
Great suggestions but bear with me while I add some additional convention info.
-
Not this one please. If any, and I still do not agree with this one, it should be “id”.
-
It should probably default to a reference field in any case if it’s “tablename_id” and pick the type of the PK of “tablename”. People could be using UUID or similar for ids which are strings.
-
Should be columns ending with “_at”
-
Ok
a) Date fields are achieved via knex type “timestamps”. There is already a FR opened for this. It will create “updated_at” and “created_at” fields and default them to now() (at creation). You still need to create triggers when the row is updated every time.
b) Created_by and updated_by are a nice addition indeed(but should be optional).
- Ok
2 Likes
Correct - let me make my case on tablename_id.
I use tablename_id (i.e. I have a customer table and I create customer_id as the customer primary key.)
I know Jon disagrees and I can see his argument - it’s nice and clean to call the PK id. I completely agree- in theory.
In many database IDEs when you join and have 2 columns of the same name, the IDE automatically picks the correct column to join to.
I find it’s also clearer when you are using the field in the UI and you don’t have to alias multiple ID columns to know which id is which.
Example:
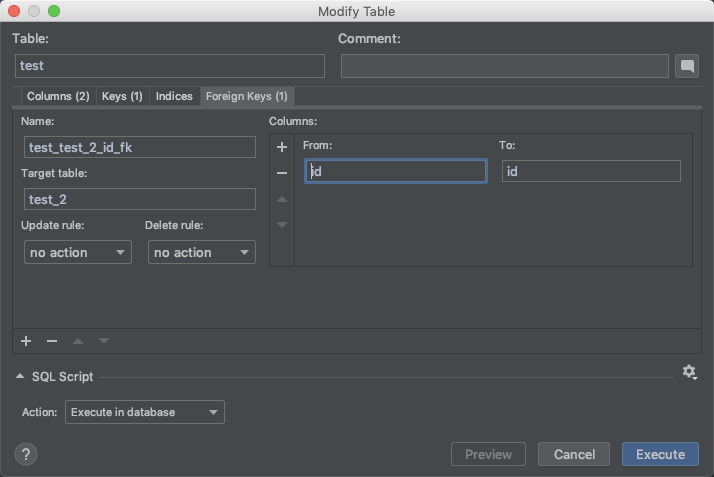
I created a table test and test2, both with id fields.
Before I create a foreign key - I have to type the whole query (using Datagrip):

I create my foreign key and the IDE automatically chooses the matching id columns:
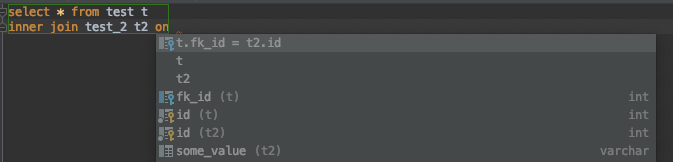
After the FK is defined - typeahead works:
But then in Wappler and I do a join…here’s what happens
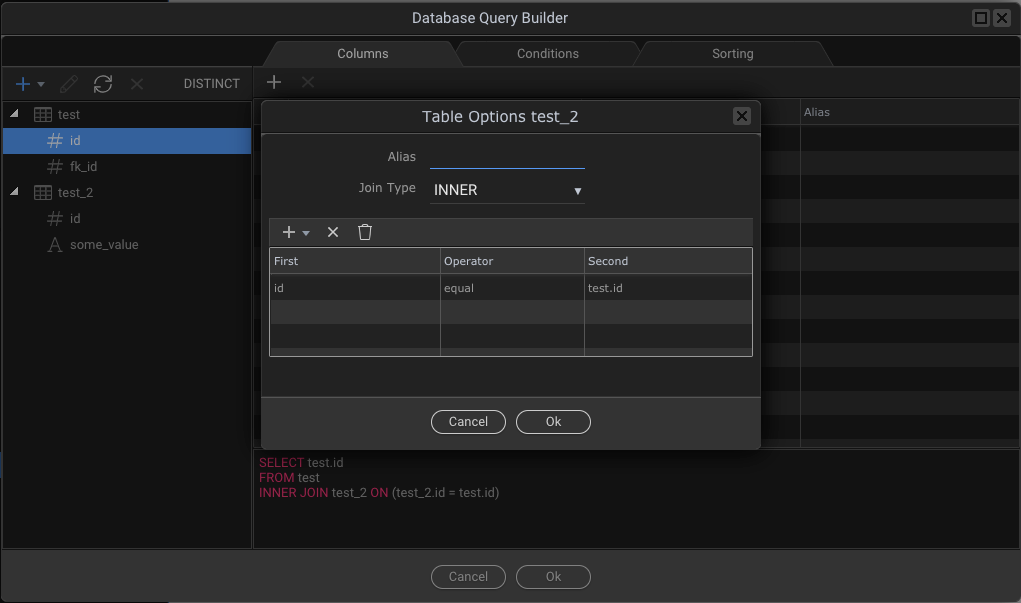
The evidence suggests that most professional database IDE companies expect tablename_id. 
If you decide after my compelling arguments that you like ID better  , then I’d recommend picking up the foreign key references on the joins.
, then I’d recommend picking up the foreign key references on the joins.
And - since you have proven that you are the most efficient development team in the world, I’m expecting these will be done in version 3.4.3 on Friday 
1 Like
Some thoughts to consider:
With regards to CrystalTaggart’s points, keep in mind that not all of us use the same table naming conventions.
On points 1 and 2
For a primary key, we use TablenameID, but I think SQL Workbench uses idTABLENAME. What seems to be widely present is the string id, somewhere in the name, and capitalized or not. Maybe Wappler can implement it using a regex search for variants on ID, maybe at the beginning of the name or at its end. This may still give errors if there’s a column name like Identifier, but I think most of us will be able to live with that.
Point 3
Similar considerations. Not everyone uses the convention of xxx_date. I tend to use XxxxDate.
Point 4
Agree.
Point 5
Record control fields are indeed a useful thing but again, not all of us use the same naming conventions. For example, we use
- CreatedOn DATETIME defaulted to NOW() on creation
- UpdatedOn DATETIME defaulted to NOW() on update
- DisabledOn DATETIME defaulted to NULL
- CreatedBy INT
- UpdatedBy INT
- DisabledBy INT
The last three are references to the user ID.
Maybe the way to deal with this is to allow us to configure the n columns that we’ll want added to each table on creation, including the name, type, defaults, whether NULLs are allowed, whether it should autoincrement etc. JonL may add his ID column to those defaults.
Hope this helps,
Alex
I think we will be adding some global Wappler options to allow you to choose your ID convention
Also @crystaltaggart Wappler joins already have some ID matching logic but they can be improved much more indeed. To even do automatic joins based on the db scheme as we already know all the relations.
2 Likes
I don’t think it will be possible to arrive at a consensus regarding naming conventions. To be useful/useable, I think there would have to be some facility to set defaults - eg, for primary key:
id / tablenameid / tablename_id / idTablename / id_Tablename etc.
But it might just become too complicated.
I haven’t really used the Database Manager yet, but even if it had these extra features, I think I would stick to Navicat. I hardly ever create a table from scratch - I duplicate an existing table and modify it. Wouldn’t it perhaps be more useful, and simpler, to have an option to duplicate/clone an existing table - eg a table similar to what you need or a table used just as a template, which could include any default fields you use etc.
Best idea of all ![]()
Sorry - I missed @George's comment about this. That would be one issue resolved, for one column, but then there are all the other suggesions. I still would have thought duplicating an existing table, would be more useful.
From Wappler’s DB Manager perspective it wouldn’t make much sense I think because of migrations which is core to database change management.
Also, I haven’t duplicated a DB table in my whole life. I have difficulty to understand in what context I would want to do that. I’ve never had two tables with the same structure so I fail to see how it would help(me).
Of course this is just me. Maybe it is useful for others. Still you would have to decide what happens with migrations for that new table.
1 Like
I often have tables with identical or similar structures, for different sites/customers. However, even if they’re only slightly similar, perhaps containing fields I might typically include in most tables, I’ll usually start by copying an existing table.
In the same way, I would rarely create a page from scratch while working on a project, once there were existing pages to use as templates.
It may be that this approach isn’t relevant in this context as I’m used to updating tables with Navicat, perhaps in a less sophisticated way.
Oh, ok. Copying from one DB to another one makes more sense. Like for example the user table or system-wide tables. I was thinking about duplicating in the same database. That is why I had a hard time understanding usefulness. Still it is just dumping an SQL file with only the structure and importing in another DB. But the DB manager doesn’t focus on cross-app db functionality.
I meant that too. In the same way as I might copy/paste a block of code, I might copy/paste tables or parts of a table structure (which is essentially just copying code).
So maybe templates would be more useful? Something like:
https://dev.mysql.com/doc/workbench/en/wb-design-table-templates.html
This fits better Wappler’s DB manager and it is compatible with migration files.
1 Like
(I think you’ve answered by question)
That looks like a useful feature. Do you mean useful in relation to the development of Wappler’s Database Manager?
1 Like
I agree it would be useful and I think it fits better your use case. Because, correct me if I am wrong, you are duplicating tables to copy the structure and then changing it(or not) to adopt the final form. So basically you are using real live tables as templates to make you more productive.
Better then to have an actual template library you can reuse for all your projects that fits DB Manager and generates automatically a migration when used.
@George would something like this be feasible?
https://dev.mysql.com/doc/workbench/en/wb-design-table-templates.html
1 Like
Exactly. A template library would seem to be a good of way of resolving the different suggestions and approaches mentioned in this thread.
Not with you on this one @JonL, prefer the table name prefix, making them all id is confusing and counter productive .