So just a general chat for some of your thoughts and experiences on how you might (or have) go about handling and/or deploying a multi-tenant app from a Wappler side of things?
So firstly, not looking for a general pros’/cons of multi-tenancy, I’ve read lots and have seen links on here. I think at this stage id either be looking at a ‘database per tenant’ or a ‘schema per tenant’ solution and just starting to wonder how that would be handled in Wappler at a high level.
Would you need to create a new target Wappler project for each tenant (clone from GIT), change the DB name/connection details and then deploy to target?
Are there ways that Docker can make it easier?
What are the considerations from a Wappler perspective.
There’s lots of articles explaining it, but the three main types of Multi-Tenant architecture se to be:
Types of multi-tenancy
There are 3 main types of multi-tenant architecture:
(1) Multi-tenancy with a single multi-tenant database: This is the simplest form of multi-tenancy. It uses single application instance and the single database instance to host the tenants and store/retrieve the data. This architecture is highly scalable, and when more tenants are added the database is easily scaled up with more data storage. This architecture is low-cost due to shared resources. Operational complexity is high, especially during application design and setup.
(2) Multi-tenancy with one database per tenant: This is another type of multi-tenancy. It uses a single application instance and an individual database for each tenant. The scalability of this architecture may be lower and the cost higher than multi-tenancy with a single multi-tenant database because each database adds overhead. We can increase the scalability of this architecture by adding more database nodes but it depends on the workload. Operational complexity is low due to usage of individual databases.
(3) Standalone single-tenant app with single-tenant database: In this architecture you install the whole application separately for each tenant. Each tenant has its own app instance as well as database instance. This architecture provides highest level of data isolation. The cost of this architecture is high due to the standalone applications and databases.
** Edit. Most articles don’t list this as a 3rd option, but really list an option similar to the 3nd one but instead all clients are in the same database, but seperated by their own Schema. Different DBs handle this differently though
So based on those definitions, I’m not interested in the first one where all clients/tenants data would be in the same database tables, only seperated by a client/tenant ID.
But I’m still trying to get my head around how best to manage and deploy a Wappler app if using one of the other options.
Currently my thinking would be:
Have your master project that you develop on and have a demo db attached to it.
For each new client, you’d create a new project, cloned from the master
You’d configure the different db and target settings (i.e. app sub-domain for new client)
Then deploy to production and possibly delete that project as you only need it to configure target and db settings when deploying.
Does that sound right?
Also, not knowing much about Docker (but realising it is mainly meant for apps built on a micro services architecture). Wouldn’t you be able create and deploy a new docker image/app for each client with their own target and db settings?
I’m curious as to why Option one is not desired. Is it because of the client’s pricing plan for the service they are offering? Or, is it a security concern?
For me @BruceSchueller it is a security concern that i believe my future clients will have.
I’m building a very niche B2B app and while i might not have many overall clients, they will be paying for multiple licenses of their own end users and i really want to ensure their data is isolated from other clients.
For security and i guess also speed/computation as there will be some resource heavy processes that will be run on a regular basis.
Also in my instance, on boarding a new client/customer will be a lengthy process (not like signing up to a regular SaaS product with instant access) and will already require importing data, training staff and integrating with some of their existing systems (which will differ from client to client)
I have the same security concerns that you express for your clients. The secret lies with the database. Since I am using Wappler for my development platform they do allow you to develop with the MariaDB. This is the database I am using.
First, I have encrypted the entire database (encryption-at-rest) with a 512k key which is also encrypted. This protects me from a hacker who wants to copy portions or the entire database. Next, I have the SSL Certificate that protects me with communication hacks. Thirdly, I implement Wappler security that protects me from hackers trying get in through a page. I have also encrypted the error logs that MariaDB generates. But here is the most important part. It is database normalization.
You further protect your database by hiding the data. Let me try to explain. Say you have a customer table and you wish to store their name, address, and phone numbers. Most developers would just place all this information into one table. From database design and security that would be bad. All a hacker would have to do is ID the table and gather all the information. But if it were normalized, he would have to access the customer, address, and phone number tables. Any table opened by itself would be meaningless. So instead of one table you have four. Now here is the thing, You will need to do searches on these tables and to do so you require indexes. After I identify what searches need to be performed I create a table that contains those indexes. When I do a search, I search on those indexes in that table. In other words you try not to search on the main tables (customer, address, phone number).
By doing the above you can manage a terabyte of data and secure it all within one database. Scalability is easy. Management is easy. One note: Encryption-at-rest carries a performance segregation of 3% which is basically nothing.
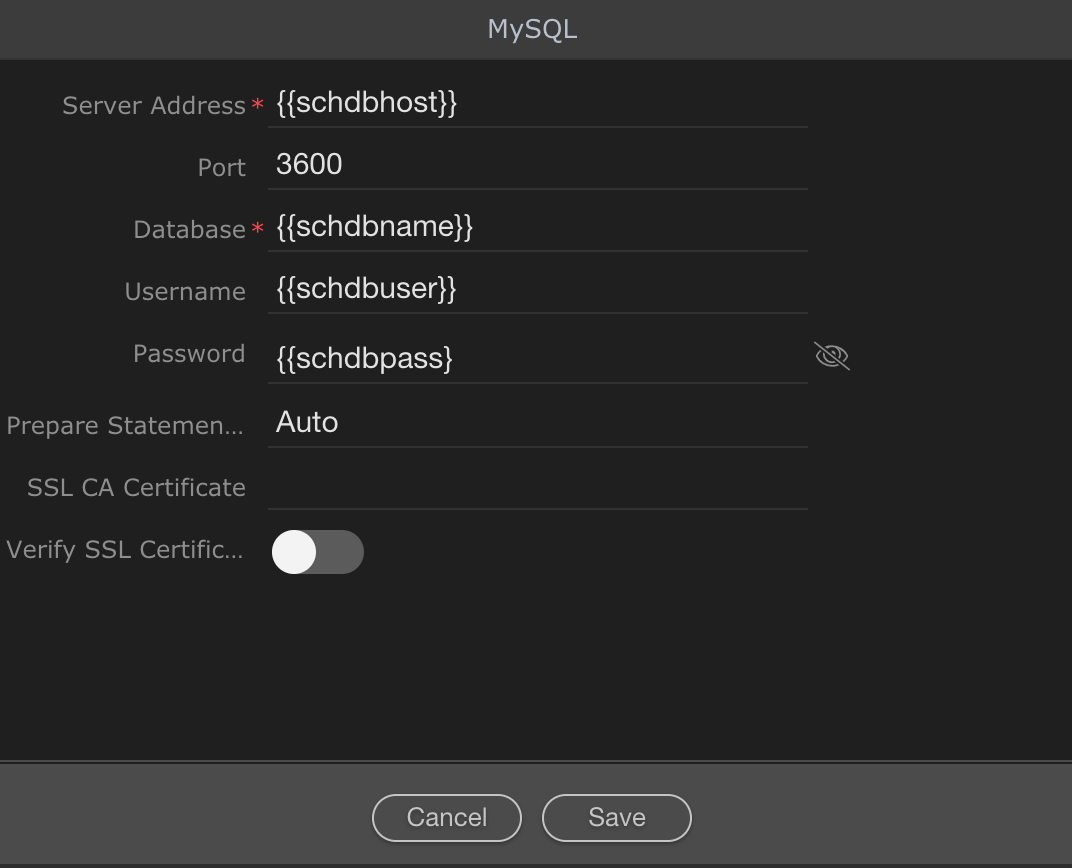
If you want to have multiple databases dynamically first single db connection in Wappler, like having for example a database per client/organization, it is all possible by using dynamic variables in the connection dialog instead of static values.
I think @creati ave experience in this building his SaaS and might be willing to share it.
Hi @george,
How is this achieved? There’s no options for data binding in DB connections and when you go on to create queries, the DB is queried to retrieve the schema, I assume some default values are needed.
I have tried using a query to retrieve the connection details from a central DB then assign them to values in SC (with a default value set to a central DB) and then enter those bindings in the connection dialog:
The way I have got around this in the past is to create my own API system that is called from Server Connect as an API Action rather than using Database Queries. I retrieve the relevant API credentials to identify the appropriate DB connection details using a query before the API is called.
It works but is fiddly because you have to maintain Wappler and a separate set of API endpoints. I would welcome a more efficient approach if anyone has suggestions.
Thanks @George,
I’ve been having a play with this and it does work well. It would be great to have dynamic connection parameters as an option in the UI
In my case I worked around it as follows (in case it helps others):
I have a central set record of DB credentials that a user retrieves once logged in to a central authentication DB (based on the organisation they are connected to). Each organisation has its own DB which can be self-hosted.
I set up a Server Connect DB connection to my central DB for the authentication.
I then set up a DB connection for a test DB that acts as my schema point (has the same structure as all organisation DBs - synced via a chronjob). When creating new SC queries, I use this connection to retrieve the DB schema.
I created a single record query to retrieve the DB connection parameters and save/linked it. This is added to all dynamic SC Server Actions before using the dynamic DB connection.
I then created the separate DB connection for the dynamic connection. I found the file in /dmxConnect/modules/Connections and opened it in the editor. I altered the connection string: "connectionString": "mysql:host={{getdbcreds.dbhost}};sslverify=true;dbname={{getdbcreds.dbname}};user={{getdbcreds.dbuser}};password={{getdbcreds.dbpass}};charset=utf8"
In my case the query that retrieved the connection parameters was called ‘getdbcreds’
Now I can set up the queries/updates/inserts etc. using the test connection which then retrieves the DB schema within the UI for data picking. I then simply switch the connection to the dynamic one.
It is worth noting that if you want to use the client-side data pickers for the query, you have to switch to the test connection in SC, use the data picker and then switch it back again as the data picker is connection specific