Hi everyone,
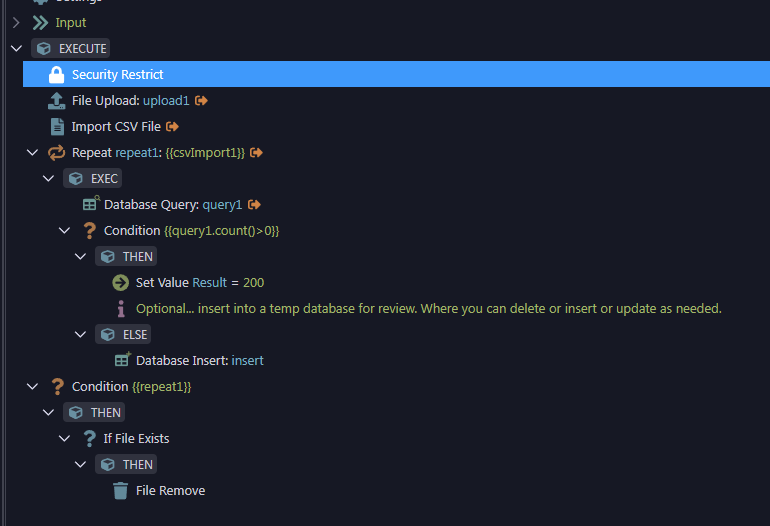
I'm working on a Wappler project where I need to insert a large batch of records into a database (MySQL in my case). However, I want to make sure that duplicate entries (based on a unique field like email or user_id) are not inserted.
Here's what I'm trying to achieve:
- Upload or provide a bulk dataset (e.g., via CSV or a JSON array).
- Loop through the dataset in Wappler.
- Before inserting each record, check if it already exists in the database based on a unique key.
- If it doesn't exist, insert the new record.
- If it does exist, skip or optionally update it.
So far, I'm using Server Connect and repeat steps to loop over the dataset, but I'm not sure how to efficiently:
- Check for duplicates inside the loop.
- Prevent duplicates without making the process slow or heavy.
- Handle bulk operations in a performant way.
Questions:
- What's the best approach in Wappler to handle this?
- Should I use conditional queries inside the repeat step, or is there a better native feature or module in Wappler to manage this?
- Are there performance best practices or recommended patterns for large imports with duplicate checks?
Any tutorials, step-by-step guides, or examples would be greatly appreciated!
Thanks in advance ![]()