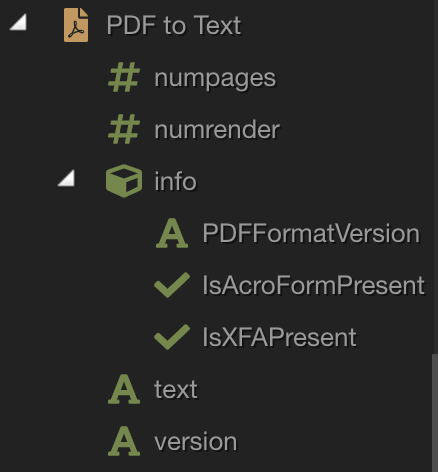
I have 2 small suggestions:
- Add square brackets to the hjson
- Add pdf-extraction to usedModules
This way, supposedly, the module is automatically installed. Not totally sure, but it is mentioned in the documentation. Perhaps it should also be added to the dockerfile for the remote targets.
Here is my working code:
[
{
type: 'PDFtoText_getValue',
module : 'pdftotext',
action : 'getValue',
groupTitle : 'My Modules',
groupIcon : 'fas fa-lg fa-project-diagram comp-images',
title : 'PDF to Text',
icon : 'fas fa-lg fa-file-pdf comp-images',
usedModules : {
node: {
"pdf-extraction": "^1.0.2"
}
},
dataScheme: [
{ name: 'numpages', type: 'number' },
{ name: 'numrender', type: 'number' },
{ name: 'info', type: 'object', sub: [
{ name: 'PDFFormatVersion', type: 'text' },
{ name: 'IsAcroFormPresent', type: 'boolean' },
{ name: 'IsXFAPresent', type: 'boolean' }
]},
{ name: 'text', type: 'text' },
{ name: 'version', type: 'text' }
],
dataPickObject: true,
properties : [
{
group: 'Source File',
variables: [
{ name: 'name', optionName: 'name', title: 'Name', type: 'text', required: true, defaultValue: ''},
{ name: 'path', optionName: 'path', title: 'Path', type: 'file', required: true, defaultValue: '', serverDataBindings: true},
{ name: 'output', optionName: 'output', title: 'Output', type: 'boolean', defaultValue: false }
]
}
]
}
]