I don't know why I keep getting this error message? I just don't quite understand how many tokens I'm using, or how many are required etc. I have the pay version of github for the AI stuff. And I get these 400 errors all the time...
If your chat has been going on for a long time (a lengthy chat session) then it is better to start a new chat as Claude summarises the entire prior chat (periodically). This consumes more tokens, which can lead to exceeding the capacity allocated, as the request may be larger than that of your prompt contents alone. Maybe that is what has occurred?
I'm not sure what's going on. Usually it works right up to the point where its solving my problem. and then that's when I get it. LOL
I mean the one I posted wasn't very long or complicated.
One other thing too is, I guess, I have a lot of commented out code. I'm changing the way I'm doing things on a page, so I just comment out the code I am not ready to get rid of. So when its going through my code, is it scanning that and is it eating more tokens because of that comments out code? And/or is there a way to tell it to not analyze commented out code?
Yes it will still read that source and count it as usage. You could try and instruct Claude to ignore code that has been commented or prefix it with a comment like below (but inform Claude of this when you prompt):
<!-- Ignore
<h1>Blah blah</h1>
-->
Or better still remove unused source all together if the above suggestion fails to work...
The statistics above the chat show the total used tokens and the number of requests made. For Copilot it doesn't matter how many tokens you use since you pay a fixed monthly fee while with other providers you often pay for the token usage.
AI Models have several limits. First there are the Prompt Tokens, these are the tokens send to the AI and includes the system prompt, the user prompt and the history. Second the Completion Tokens, this is the answer from the AI (including tokens for reasoning). Lasts you have the Context Window which are both Prompt Tokens and Completion Tokens together.
Here the limits of some models on Copilot:
Claude Sonnet 3.5
Prompt Tokens: 90,000
Completion Tokens: 8,192
Context Window: 90,000
Claude Sonnet 3.7
Prompt Tokens: 90,000
Completion Tokens: 16,384
Context Window: 200,000
Claude Sonnet 4
Prompt Tokens: 128,000
Completion Tokens: 16,000
Context Window: 128,000
Gemini 2.0 Flash
Prompt Tokens: 128,000
Completion Tokens: 8,192
Context Window: 1,000,000
Gemini 2.5 Pro
Prompt Tokens: 128,000
Completion Tokens: 64,000
Context Window: 128,000
GPT 4o
Prompt Tokens: 64,000
Completion Tokens: 4,096
Context Window: 128,000
GPT 4.1
Prompt Tokens: 128,000
Completion Tokens: 16,384
Context Window: 128,000
GPT 5
Prompt Tokens: 128,000
Completion Tokens: 64,000
Context Window: 128,000
1 Like
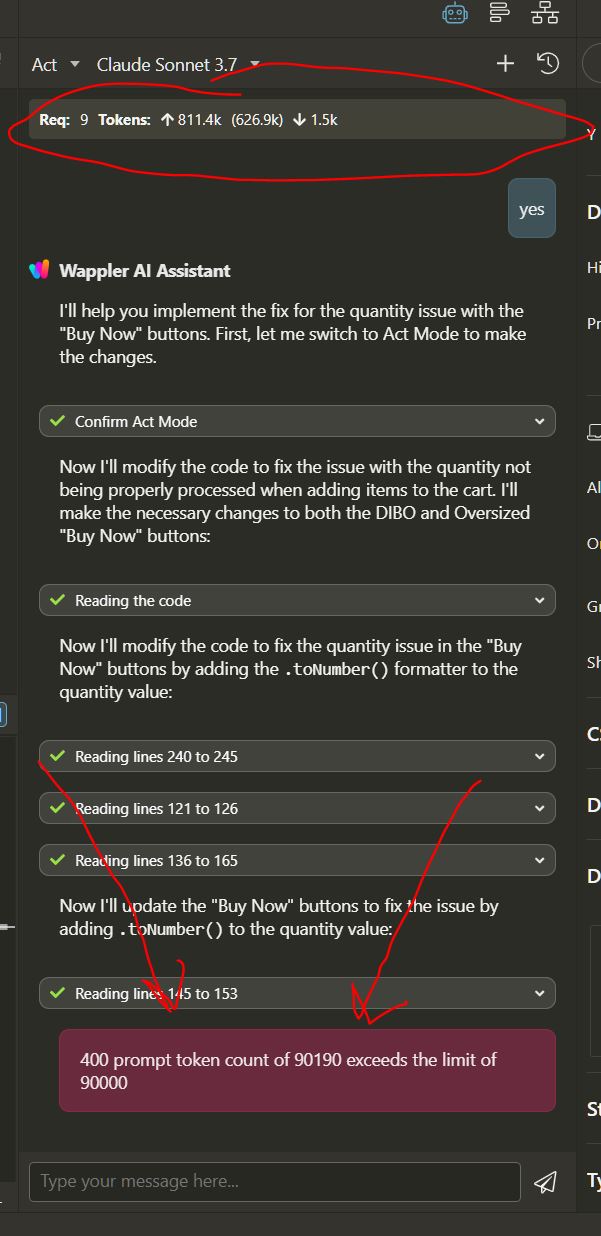
Thanks for the reply @patrick. But could you explain in more detail the top of the image posted above. Does that show my limits? Its kind of confusing. There is up arrow and down arrow etc?
The status above shows the total usage, so from the complete chat.
In your screenshot it shows:
9 requests to the AI endpoint
811.4k prompt tokens (this is the total tokens sent to the server)
626.9k cached tokens (from the prompt tokens this many were cached)
1.5k completion tokens (tokens received from the server, the responses from the AI)
1k is 1000 tokens, so the above tokens is x1000.
We could perhaps show the prompt tokens from the last request and the limit if it is known so that you know that you are almost reaching the limit. With Copilot we get the limits for each model back from the API endpoint, but with the other providers we only get the model names and we don't know the actual limit.
It is also good to know that with each request the number of tokens send to the server gets bigger since it includes the whole conversation each time. We are investigating on compressing the input when you are reaching the limit, for example by removing old messages or summarizing the conversation.
3 Likes
Ditto - numerous times. I've tried just using inside github/copilot to avoid it, but happened there too - less frequently but it happened.