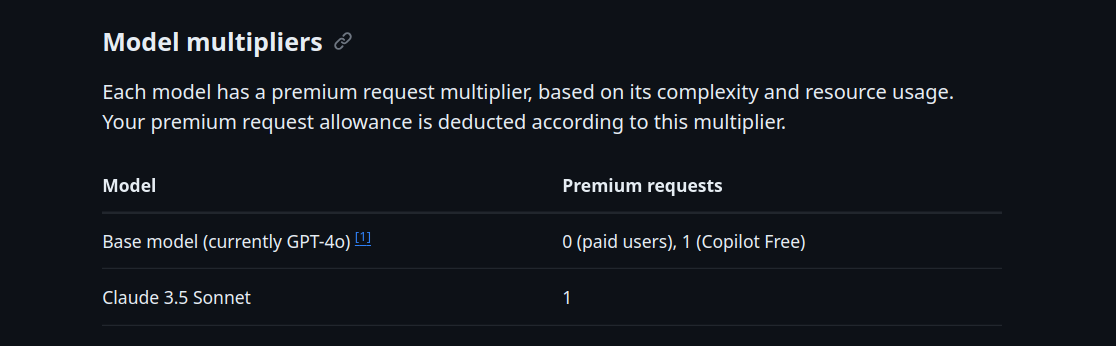
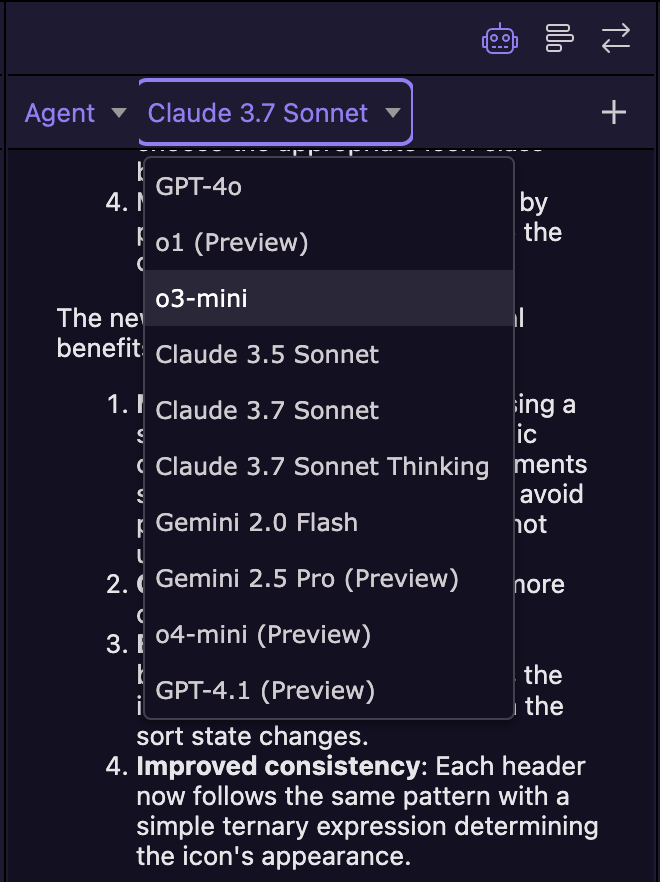
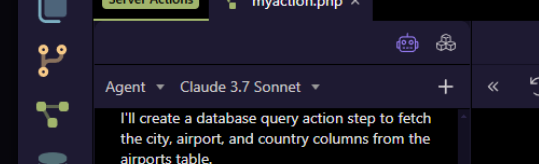
Any chance of using concepts that other applications like Cursor use?
Cursor (the AI-powered code editor based on VS Code) provides context about your project files to an LLM using a few different mechanisms:
- File System Awareness:
Cursor can scan your workspace and index project files. When you prompt the AI, it uses a context window to include relevant files—often the one you're working on plus others it deems necessary based on dependencies or imports.
- Selective Context Injection:
Cursor intelligently selects which files or snippets to load into the prompt. It typically includes:
The current file you're editing.
Related files (e.g., imported modules, configuration files).
File summaries or embeddings if full files are too large.
Some versions allow you to manually specify which files to include for more control.
- Embeddings & Retrieval:
For larger projects, Cursor might use vector embeddings. It creates compressed representations of files and retrieves the most relevant parts based on your query, then includes those in the LLM's prompt.
- Session Memory:
During a session, Cursor keeps track of your activity, including files opened, functions edited, and previous interactions with the AI. This builds a more cohesive context without needing to re-parse the entire project.
- LLM Prompt Engineering:
Cursor uses advanced prompt engineering to construct the prompt sent to the LLM. It might summarize parts of files, include file names and line numbers, or highlight recent changes.
If you're using a local model or API, Cursor can sometimes allow configuration on how much context to pass or even let you inspect the raw prompts for transparency.
You can explicitly instruct Cursor’s LLM to search the codebase, and here’s how that typically works under the hood:
- Explicit Codebase Search Command:
Cursor allows commands like "search the codebase for all instances of X" or "find where function Y is used."
When you do this, Cursor uses a code-aware search (like ripgrep or similar) to locate relevant files/snippets.
The results of that search are then pulled into the LLM’s context window on-demand.
- Dynamic Context Expansion:
After the initial search, Cursor dynamically expands the LLM’s prompt with:
Relevant file paths.
Code snippets from those files (possibly trimmed to fit the token limit).
Short summaries or headings around the found code for better grounding.
- Interactive Refinement:
You can then refine your instruction. For example, after a search, you can say:
"Refactor all of these functions."
"Generate tests for all methods in these files."
Cursor fetches additional context only as needed and keeps prior results in short-term memory.
- Behind the Scenes:
File Embeddings (Optional): Some setups support vector-based search across the codebase, allowing for semantic code search.
File Previews: You can view which files/snippets are being fed to the LLM.
Partial Loading: If files are large, Cursor may chunk them and only load the most relevant chunks based on your query.
Example Flow:
-
You: "Where is validateUserInput used in the codebase?"
-
Cursor: Searches all project files → finds 3 instances → loads those snippets into the LLM.
-
You: "Update all of them to also log the user ID."
-
Cursor: Edits each usage based on the LLM's instructions with the full context of each usage loaded.
Why It Matters:
This hybrid approach (LLM + local/project search) lets you leverage AI over large codebases without blowing past context/token limits.
You’re effectively steering the LLM, telling it what to include, search, or ignore.