Hi,
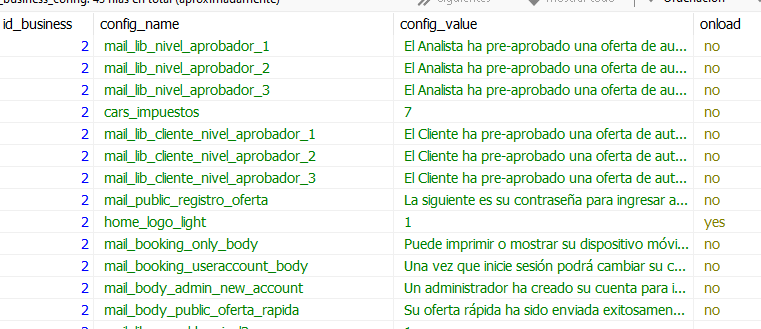
I have a table that works to populate the info into a form that allow to user to later change these info or not, in my case it works to populate business config using two columns “config_name” and “config_value”, some rows are simple values and others contain json data.
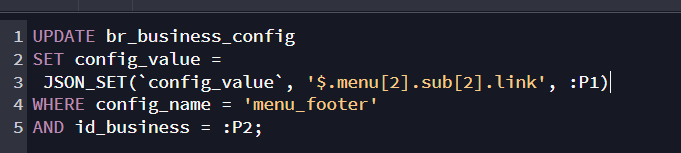
The API has a simple “Database Query” to the table and then I use “Set Value” to obtain each config_value from each “config_name” using WHERE clause inside each “Set Value”.
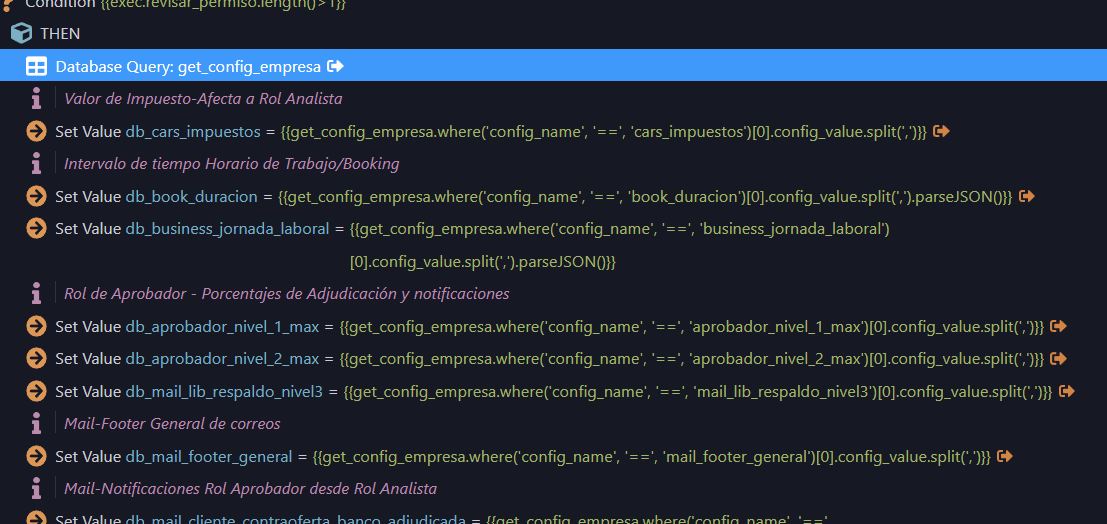
The API looks like this, some “Set Value” retrieve simple data and others json using “parseJSON” at end, but all from same “Database Query”. All “Set Value” are output because need it to populate in form.
(Image 1)
The table looks like this:
(Image 2)
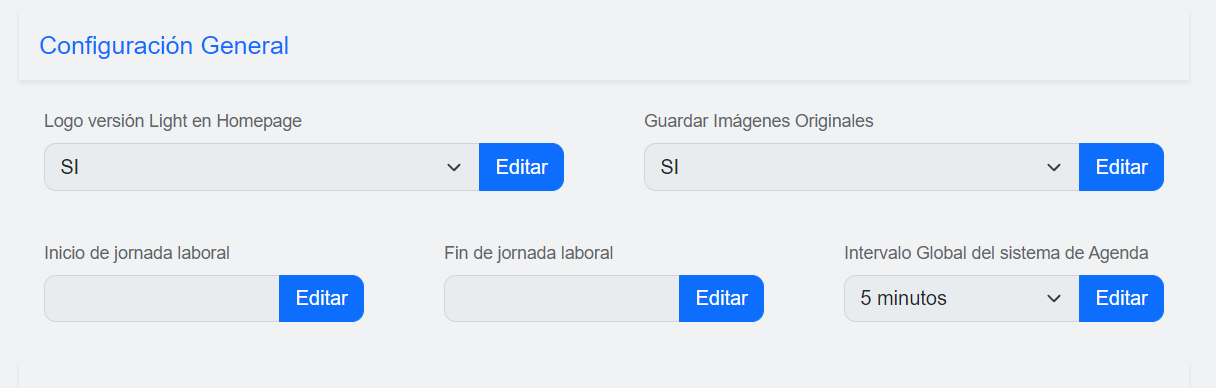
And in the cliente side, the front is something like this:
(Image 3)
Now my question is if the use of “Set Value” using WHERE clause cause that each one query into the “Database Query” and at same time ocurr a real query into database, I mean, if each “Set Value” means a direct query into database?.
In API (Image 1) is a cutted image, really the “Set Value” quantity are like 30, so I wonder if each “Set Value” cost performance to database, or, like each “Set Value” is querying from the same “Database Query” it take it from some cache and has not cost in performance.
And at same time. I know that each “Set Value” using WHERE clause can be translate into Client Side, for example:
sc_config_business.data.get_config_empresa.where('config_name', 'home_total_muebles', '==')[0].config_value
But I wonder if performance is the same in Client side that Server Side using the “Set Value”.
In this old blog (2008) from percona site: https://www.percona.com/blog/how-expensive-is-a-where-clause-in-mysql/, says that the cost with a simple WHERE clause cause between 60 and 80%, so, my concern is in trying to build something maybe “future proof” keeping in mind that that table grow every time.
I would really like your help with this, I don’t know if it is the best approach, or I’m doing something wrong.
Thanks.