Regarding versioning. Check this out for mariadb:
It looks promising.
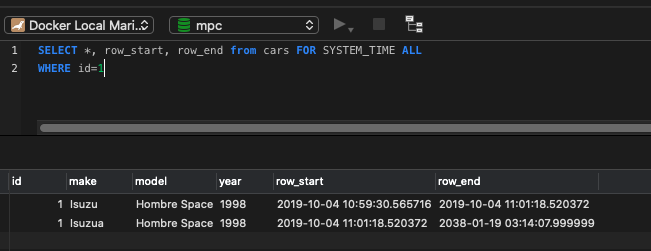
You need to add row_start and row_end to the SELECT statement as they are system columns generated by the versioning system.
Regarding versioning. Check this out for mariadb:
It looks promising.
You need to add row_start and row_end to the SELECT statement as they are system columns generated by the versioning system.